Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
LessWrong에서 제공하는 콘텐츠입니다. 에피소드, 그래픽, 팟캐스트 설명을 포함한 모든 팟캐스트 콘텐츠는 LessWrong 또는 해당 팟캐스트 플랫폼 파트너가 직접 업로드하고 제공합니다. 누군가가 귀하의 허락 없이 귀하의 저작물을 사용하고 있다고 생각되는 경우 여기에 설명된 절차를 따르실 수 있습니다 https://ko.player.fm/legal.
LessWrong (Curated & Popular)와 비슷한 콘텐츠
We help founders make something people want.
…
continue reading
A podcast featuring panelists of engineers from Netflix, Twitch, & Atlassian talking over drinks about all things software engineering.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
The Fragmented Podcast is the leading Android developer podcast started by Kaushik Gopal & Donn Felker. Our goal is to help you become a better Android Developer through conversation & to capture the zeitgeist of Android development. We chat about topics such as Testing, Dependency Injection, Patterns and Practices, useful libraries, and much more. We will also be interviewing some of the top developers out there. Subscribe now and join us on the journey of becoming a better Android Developer.
…
continue reading
Discover a whole new take on Artificial Intelligence with Squirro's educational podcast! Join host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and their incredible impact on society, and y ...
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 13 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell (@jcutrell), co-founder of Spec and Director of Engineering at PBS. We hope you'll take the topics from this podcast and continue the conversation, either online or in person with your peers. Twitter: @developertea :: Email: deve ...
…
continue reading
Monday through Friday, Marketplace demystifies the digital economy in less than 10 minutes. We look past the hype and ask tough questions about an industry that’s constantly changing.
…
continue reading
Talk Python to Me is a weekly podcast hosted by developer and entrepreneur Michael Kennedy. We dive deep into the popular packages and software developers, data scientists, and incredible hobbyists doing amazing things with Python. If you're new to Python, you'll quickly learn the ins and outs of the community by hearing from the leaders. And if you've been Pythoning for years, you'll learn about your favorite packages and the hot new ones coming out of open source.
…
continue reading
Player FM -팟 캐스트 앱
Player FM 앱으로 오프라인으로 전환하세요!
Player FM 앱으로 오프라인으로 전환하세요!

))
“Current safety training techniques do not fully transfer to the agent setting” by Simon Lermen, Govind Pimpale
Manage episode 449300751 series 3364760
LessWrong에서 제공하는 콘텐츠입니다. 에피소드, 그래픽, 팟캐스트 설명을 포함한 모든 팟캐스트 콘텐츠는 LessWrong 또는 해당 팟캐스트 플랫폼 파트너가 직접 업로드하고 제공합니다. 누군가가 귀하의 허락 없이 귀하의 저작물을 사용하고 있다고 생각되는 경우 여기에 설명된 절차를 따르실 수 있습니다 https://ko.player.fm/legal.
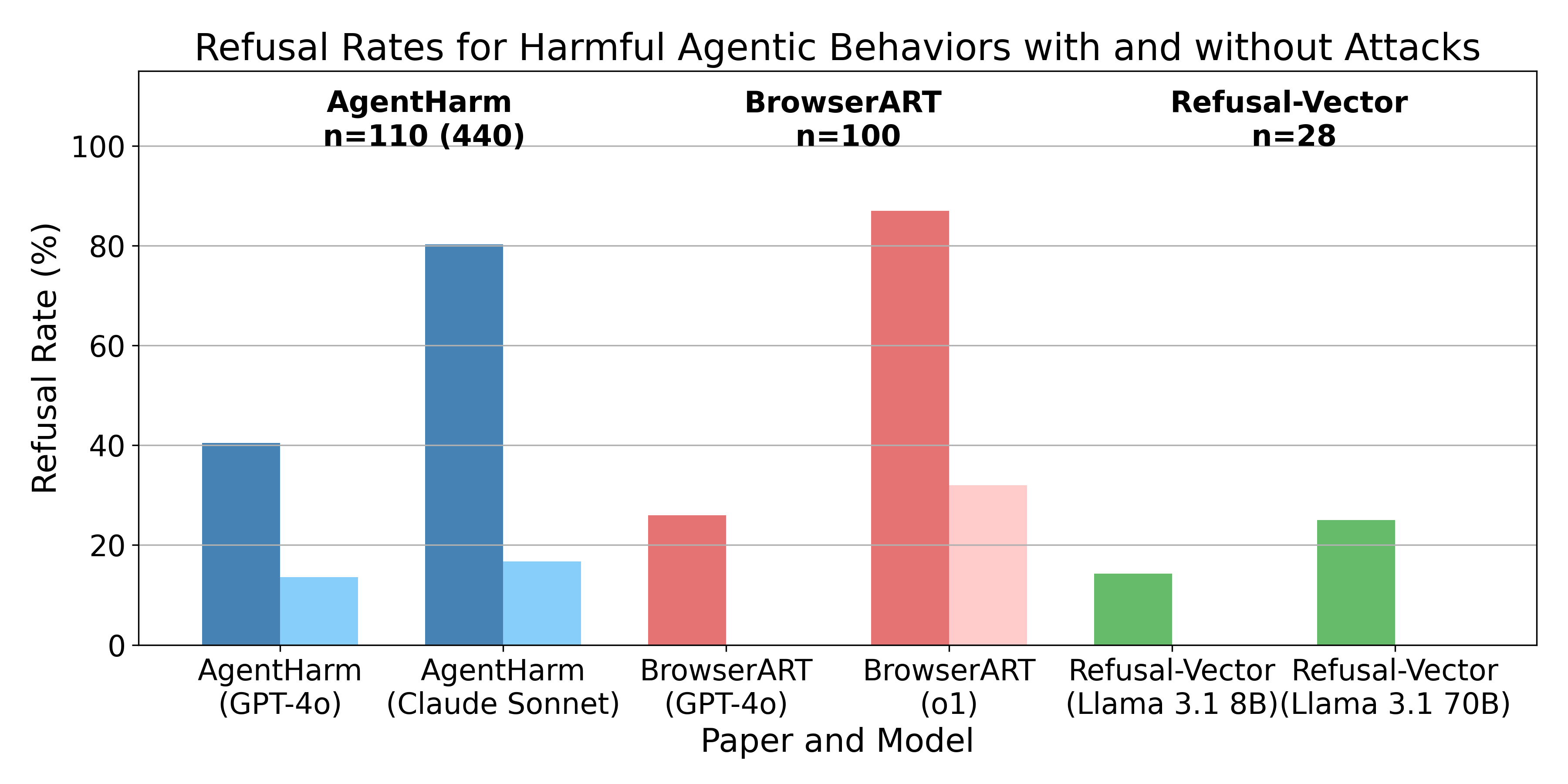
TL;DR: I'm presenting three recent papers which all share a similar finding, i.e. the safety training techniques for chat models don’t transfer well from chat models to the agents built from them. In other words, models won’t tell you how to do something harmful, but they are often willing to directly execute harmful actions. However, all papers find that different attack methods like jailbreaks, prompt-engineering, or refusal-vector ablation do transfer.
Here are the three papers:
Language model agents are a combination of a language model and a scaffolding software. Regular language models are typically limited to being chat bots, i.e. they receive messages and reply to them. However, scaffolding gives these models access to tools which they can [...]
---
Outline:
(00:55) What are language model agents
(01:36) Overview
(03:31) AgentHarm Benchmark
(05:27) Refusal-Trained LLMs Are Easily Jailbroken as Browser Agents
(06:47) Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
(08:23) Discussion
---
First published:
November 3rd, 2024
Source:
https://www.lesswrong.com/posts/ZoFxTqWRBkyanonyb/current-safety-training-techniques-do-not-fully-transfer-to
---
Narrated by TYPE III AUDIO.
---
…
continue reading
Here are the three papers:
- AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
- Refusal-Trained LLMs Are Easily Jailbroken As Browser Agents
- Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
Language model agents are a combination of a language model and a scaffolding software. Regular language models are typically limited to being chat bots, i.e. they receive messages and reply to them. However, scaffolding gives these models access to tools which they can [...]
---
Outline:
(00:55) What are language model agents
(01:36) Overview
(03:31) AgentHarm Benchmark
(05:27) Refusal-Trained LLMs Are Easily Jailbroken as Browser Agents
(06:47) Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
(08:23) Discussion
---
First published:
November 3rd, 2024
Source:
https://www.lesswrong.com/posts/ZoFxTqWRBkyanonyb/current-safety-training-techniques-do-not-fully-transfer-to
---
Narrated by TYPE III AUDIO.
---
Images from the article:
 Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.372 에피소드
Manage episode 449300751 series 3364760
LessWrong에서 제공하는 콘텐츠입니다. 에피소드, 그래픽, 팟캐스트 설명을 포함한 모든 팟캐스트 콘텐츠는 LessWrong 또는 해당 팟캐스트 플랫폼 파트너가 직접 업로드하고 제공합니다. 누군가가 귀하의 허락 없이 귀하의 저작물을 사용하고 있다고 생각되는 경우 여기에 설명된 절차를 따르실 수 있습니다 https://ko.player.fm/legal.
TL;DR: I'm presenting three recent papers which all share a similar finding, i.e. the safety training techniques for chat models don’t transfer well from chat models to the agents built from them. In other words, models won’t tell you how to do something harmful, but they are often willing to directly execute harmful actions. However, all papers find that different attack methods like jailbreaks, prompt-engineering, or refusal-vector ablation do transfer.
Here are the three papers:
Language model agents are a combination of a language model and a scaffolding software. Regular language models are typically limited to being chat bots, i.e. they receive messages and reply to them. However, scaffolding gives these models access to tools which they can [...]
---
Outline:
(00:55) What are language model agents
(01:36) Overview
(03:31) AgentHarm Benchmark
(05:27) Refusal-Trained LLMs Are Easily Jailbroken as Browser Agents
(06:47) Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
(08:23) Discussion
---
First published:
November 3rd, 2024
Source:
https://www.lesswrong.com/posts/ZoFxTqWRBkyanonyb/current-safety-training-techniques-do-not-fully-transfer-to
---
Narrated by TYPE III AUDIO.
---
…
continue reading
Here are the three papers:
- AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
- Refusal-Trained LLMs Are Easily Jailbroken As Browser Agents
- Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
Language model agents are a combination of a language model and a scaffolding software. Regular language models are typically limited to being chat bots, i.e. they receive messages and reply to them. However, scaffolding gives these models access to tools which they can [...]
---
Outline:
(00:55) What are language model agents
(01:36) Overview
(03:31) AgentHarm Benchmark
(05:27) Refusal-Trained LLMs Are Easily Jailbroken as Browser Agents
(06:47) Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
(08:23) Discussion
---
First published:
November 3rd, 2024
Source:
https://www.lesswrong.com/posts/ZoFxTqWRBkyanonyb/current-safety-training-techniques-do-not-fully-transfer-to
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.372 에피소드
सभी एपिसोड
×플레이어 FM에 오신것을 환영합니다!
플레이어 FM은 웹에서 고품질 팟캐스트를 검색하여 지금 바로 즐길 수 있도록 합니다. 최고의 팟캐스트 앱이며 Android, iPhone 및 웹에서도 작동합니다. 장치 간 구독 동기화를 위해 가입하세요.
LessWrong (Curated & Popular)와 비슷한 콘텐츠
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
We help founders make something people want.
…
continue reading
A podcast featuring panelists of engineers from Netflix, Twitch, & Atlassian talking over drinks about all things software engineering.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
The Fragmented Podcast is the leading Android developer podcast started by Kaushik Gopal & Donn Felker. Our goal is to help you become a better Android Developer through conversation & to capture the zeitgeist of Android development. We chat about topics such as Testing, Dependency Injection, Patterns and Practices, useful libraries, and much more. We will also be interviewing some of the top developers out there. Subscribe now and join us on the journey of becoming a better Android Developer.
…
continue reading
Discover a whole new take on Artificial Intelligence with Squirro's educational podcast! Join host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and their incredible impact on society, and y ...
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 13 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell (@jcutrell), co-founder of Spec and Director of Engineering at PBS. We hope you'll take the topics from this podcast and continue the conversation, either online or in person with your peers. Twitter: @developertea :: Email: deve ...
…
continue reading
Monday through Friday, Marketplace demystifies the digital economy in less than 10 minutes. We look past the hype and ask tough questions about an industry that’s constantly changing.
…
continue reading
Talk Python to Me is a weekly podcast hosted by developer and entrepreneur Michael Kennedy. We dive deep into the popular packages and software developers, data scientists, and incredible hobbyists doing amazing things with Python. If you're new to Python, you'll quickly learn the ins and outs of the community by hearing from the leaders. And if you've been Pythoning for years, you'll learn about your favorite packages and the hot new ones coming out of open source.
…
continue reading
Player FM -팟 캐스트 앱
Player FM 앱으로 오프라인으로 전환하세요!
Player FM 앱으로 오프라인으로 전환하세요!



